What is Hazelcast Auto DB Integration?
Hazelcast Auto DB Integration is a development tool for projects involving connecting existing RDBMS to Hazelcast IMDG.
It can be used to automatically extract metadata from an existing database and generate code that supports features of the underlying database, the Hazelcast client, and IMDG. It provides an automatically generated domain model including POJOs (Portable), SerializationFactories, ClassDefinitions, MapStores, MapLoaders, ClientConfiguration, Ingest, Index and more. The generated domain model is compatible with Hazelcast Enterprise functions such as High-Density Memory Store, Hot Restart Store, Management Center etc.
Hazelcast Auto DB Integration is a part of the Speedment Enterprise Suite since version 3.1.13.
Main Features
Using the Hazelcast Auto DB Integration, Speedment can greatly simplify working with Hazelcast and can, from an existing database, automatically generate:
- Java domain data model (e.g. entities)
- Hazelcast Serialization support
- Hazelcast MapStore/MapLoad support
- Hazelcast configuration handling
- Hazelcast indexing based on the underlying database indexing
- Persistence handling
In addition to this, the Hazelcast Auto DB Integration also provides:
- Automatic ingest of data from an existing database to the Hazelcast grid
- Access to the Hazelcast grid for additional languages such as
- C++
- node.js
- C#
- Go
- Python
- and many other languages
Architecture
The Hazelcast Auto DB Integration support storage of entities in distributed maps in a client/server architecture whereby the HazelcastBundle runtime only needs to reside on the client side. No extra software is required on the server side which allows easy setup, migration and management of Hazelcast clusters.
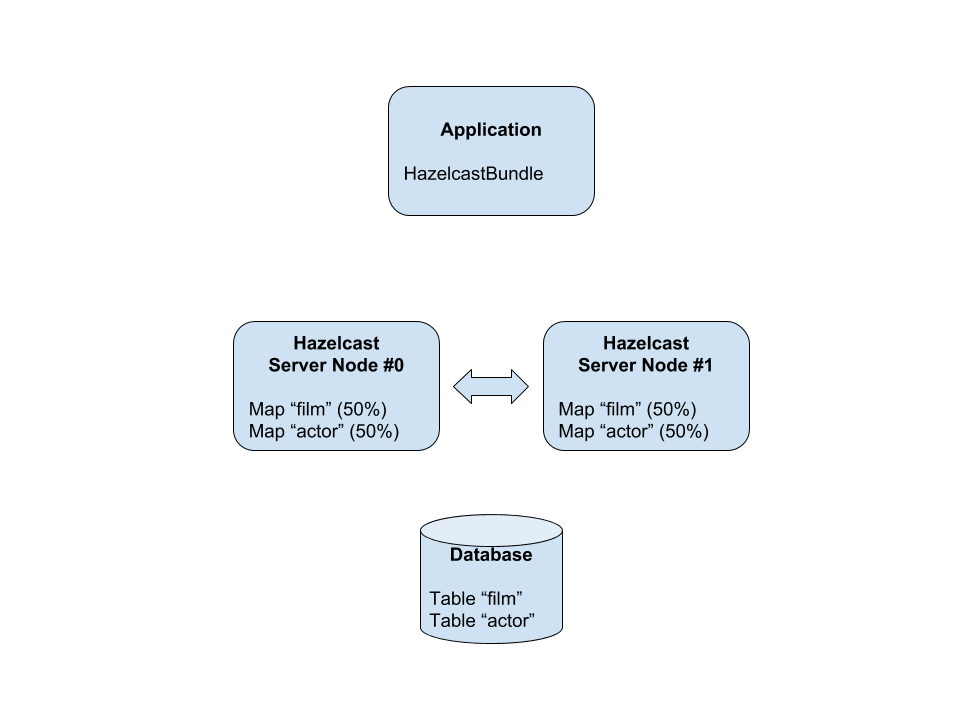
Starting from the bottom of the picture, data in this example is stored in a traditional database in two tables named “film” and “actor”.
Using the HazelcastBundle data from these tables can, via the application, easily be ingested into the Hazelcast server grid. in this example, the grid consist of two nodes “Hazelcast Server Node #0” and “Hazelcast Server Node #1”. Node #0 and #1 each holds approximately 50% of the data from the database tables in two different distributed maps.
The application can query and manipulate data in the Hazelcast server grid without touching the database.
Since the database is no longer involved in querying, application speed may be greatly improved in many cases.
Consistency across Domains
The database is considered the “Source of Truth” and the Hazelcast server grid can reflect a consistent view of the underlying database at an unspecified time. Thus, it is wrong to use data from one domain and then use it in the other domain.
If updates are made to the database by a non-Auto DN Integration application, those updates are not reflected in the Hazelcast server grid and a new ingest of data must be done to ensure consistency.
Obtaining a license
In order to use Hazelcast Auto DB Integration you need a commercial license or a trial license key. The most straight forward way of obtaining a trial license is to download a pre-initialized project via the Hazelcast Auto DB Integration Initializer.
From that page, a minimalistic starter project can be downloaded. The included pom.xml file can be used
as it is or be merged with an existing project. The first time the code generation tool is started,
the user is prompted to apply for a trial license.
For more details, see the general information about how to handle licenses in Speedment products.
Installing the Hazelcast Bundles
There are two Hazelcast bundles that need to be installed:
HazelcastToolBundlethat is needed by the UI Tool to generate entity classes and other support classes (generation)HazelcastBundlethat is needed at runtime by the Hazelcast client application (runtime)
Hazelcast applications running under the Java Module System (JPMS) needs to require com.speedment.enterprise.hazelcast.runtime; in the module-info.java file.
Installing the HazelcastToolBundle
In the pom.xml file, the speedment-enterprise-maven-plugin configuration needs to be updated so that the HazelcastToolBundle class is added and the hazelcast-tool dependency is added:
<plugins>
<plugin>
<groupId>com.speedment.enterprise</groupId>
<artifactId>speedment-enterprise-maven-plugin</artifactId>
<version>${speedment.version}</version>
<configuration>
<components>
<!-- Add the following component to this plugin -->
<component>com.speedment.enterprise.hazelcast.tool.HazelcastToolBundle</component>
</components>
<appName>${project.artifactId}</appName>
<packageName>${project.groupId}</packageName>
</configuration>
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
<scope>runtime</scope>
</dependency>
<!-- The dependency below needs to be added -->
<dependency>
<groupId>com.speedment.enterprise.hazelcast</groupId>
<artifactId>hazelcast-tool</artifactId>
<version>${speedment.version}</version>
</dependency>
</dependencies>
</plugin>
</plugins>
Installing the HazelcastBundle
In the pom.xml file, the following dependencies needs to be added to make the HazelcastBundle present on the classpath:
<dependencies>
<!-- other dependencies -->
<dependency>
<groupId>com.speedment.enterprise.hazelcast</groupId>
<artifactId>hazelcast-runtime</artifactId>
<version>${speedment.version}</version>
</dependency>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast-client</artifactId>
<version>3.11</version>
</dependency>
</dependencies>
In the application builder, the HazelcastBundle needs to be added to allow injection of the Hazelcast runtime components as shown in this example:
final Speedment hazelcastApp = new SakilaApplicationBuilder()
.withPassword("sakila-password")
.withBundle(HazelcastBundle.class)
.build();
Entities
Hazelcast compatible data entities are automatically generated from the database metadata. The generated entities implements Hazelcast’s Portable interface.
Hazelcast serialization and Map handling involves several aspects as described in this chapter.
In all the code examples below, the Sakila sample database are being used. The Sakila database is also available as a Docker instance.
Serialization
The HazelcastToolBundle automatically generates the necessary entity POJO objects including Portable serialization. For example, the implementation of the Film interface is generated like this:
public final class FilmImpl extends GeneratedFilmImpl implements Film {}
As can be seen, an entity implementation class just inherits all its methods from another generated class. This allows the possibility to override generated methods with custom code that is retained between re-generation of code.
@GeneratedCode("Speedment")
public abstract class GeneratedFilmImpl implements Film {
private int filmId;
private String title;
private String description;
private Date releaseYear;
private short languageId;
private Short originalLanguageId;
private short rentalDuration;
private BigDecimal rentalRate;
private Integer length;
private BigDecimal replacementCost;
private String rating;
private String specialFeatures;
private Timestamp lastUpdate;
protected GeneratedFilmImpl() {}
@Override
public int getFilmId() { return filmId; }
@Override
public String getTitle() { return title; }
@Override
public Optional<String> getDescription() { return Optional.ofNullable(description); }
// Rest of getters hidden for brevity
@Override
public Film setFilmId(int filmId) {
this.filmId = filmId;
return this;
}
@Override
public Film setTitle(String title) {
this.title = title;
return this;
}
@Override
public Film setDescription(String description) {
this.description = description;
return this;
}
// Rest of setters and finders hidden for brevity
@Override
public int getFactoryId() { return 1321754994;}
@Override
public int getClassId() { return 3143044; }
@Override
public void writePortable(PortableWriter writer) throws IOException {
writer.writeInt("film_id", getFilmId());
writer.writeUTF("title", getTitle());
writer.writeUTF("description", getDescription().orElse(null));
if (getReleaseYear().isPresent()){
writer.writeBoolean("__null__release_year", false);
writer.writeLong("release_year", getReleaseYear().get().getTime());
} else {
writer.writeBoolean("__null__release_year", true);
writer.writeLong("release_year", Long.MIN_VALUE);
}
writer.writeShort("language_id", getLanguageId());
if (getOriginalLanguageId().isPresent()){
writer.writeBoolean("__null__original_language_id", false);
writer.writeShort("original_language_id", getOriginalLanguageId().get());
} else {
writer.writeBoolean("__null__original_language_id", true);
writer.writeShort("original_language_id", Short.MIN_VALUE);
}
writer.writeShort("rental_duration", getRentalDuration());
writer.writeUTF("rental_rate", getRentalRate().toString());
if (getLength().isPresent()){
writer.writeBoolean("__null__length", false);
writer.writeInt("length", getLength().getAsInt());
} else {
writer.writeBoolean("__null__length", true);
writer.writeInt("length", Integer.MIN_VALUE);
}
writer.writeUTF("replacement_cost", getReplacementCost().toString());
writer.writeUTF("rating", getRating().orElse(null));
writer.writeUTF("special_features", getSpecialFeatures().orElse(null));
writer.writeLong("last_update", getLastUpdate().getTime());
}
@Override
public void readPortable(PortableReader reader) throws IOException {
setFilmId(reader.readInt("film_id"));
setTitle(reader.readUTF("title"));
setDescription(reader.readUTF("description"));
setReleaseYear(reader.readBoolean("__null__release_year")
? null
: new Date(reader.readLong("release_year")));
setLanguageId(reader.readShort("language_id"));
setOriginalLanguageId(reader.readBoolean("__null__original_language_id")
? null
: reader.readShort("original_language_id"));
setRentalDuration(reader.readShort("rental_duration"));
setRentalRate(new BigDecimal(reader.readUTF("rental_rate")));
setLength(reader.readBoolean("__null__length")
? null
: reader.readInt("length"));
setReplacementCost(new BigDecimal(reader.readUTF("replacement_cost")));
setRating(reader.readUTF("rating"));
setSpecialFeatures(reader.readUTF("special_features"));
setLastUpdate(new Timestamp(reader.readLong("last_update")));
}
// toString, equals and hashCode hidden for brevity
}
Because Portable objects cannot handle nullable wrapper classes in Hazelcast, these fields are handled with an extra synthetic fields beginning with __null__ (two understrokes at both ends).
Primary Keys
Because entities are stored in distributed maps, each entry must have a unique key. The key is extracted from an entity depending on its primary key(s) (if any). This works in the following way:
No Primary Key
A synthetic key is used in the form of a Long that generates a unique value each time an entry is added to the map. The specific sequence is undefined but it is guaranteed keys are never repeated for the same Map within the same cluster. It is not recommended to use entities with no primary key.
One Primary Key
The primary key is extracted from the entity and is used as a key in the Map. For example, if a Film entity has a primary key “film_id” that is of type int, then a corresponding Integer will be used as key. This is the recommended way for optimum performance.
Two or More Primary Keys
The primary keys are extracted from the entry and are put in a List that is used as a key in the Map. For example, if a FilmActor entity has a compound primary key consisting of the columns actor_id and film_id (both of type int), then a List containing two corresponding Integer objects will be used as key.
Portable Factories
The HazelcastToolBundle automatically generates the necessary PortableFactory objects. These are used to create Portable entities without resorting to reflection.
All PortableFactory classes are collected together in a single holder class and there is one PortableFactory for each schema in the database. For the Sakila sample database (that consist only of one schema also named “sakila”) the following classes are generated:
public final class SakilaPortableFactories {
private SakilaPortableFactories() {}
/**
* A {@link PortableFactory } class for the schema sakila
* <p>
* This PortableFactory has an id of 1321754994
*/
public final static class SakilaSakilaPortableFactory
extends GeneratedSakilaSakilaPortableFactory
implements PortableFactory {}
}
As can be seen, PortableFactory class just inherits all its methods from another generated class. This allows the possibility to override generated methods with custom code that is retained between re-generation of code.
@GeneratedCode("Speedment")
public final class GeneratedSakilaPortableFactories {
private GeneratedSakilaPortableFactories() {}
/**
* A {@link PortableFactory } class for the schema sakila
* <p>
* This PortableFactory has an id of 1321754994
*/
public abstract static class GeneratedSakilaSakilaPortableFactory implements PortableFactory {
@Override
public Portable create(int classId) {
switch (classId) {
case 92645877: return new ActorImpl();
case 1147692044: return new AddressImpl();
case 50511102: return new CategoryImpl();
case 3053931: return new CityImpl();
case 957831062: return new CountryImpl();
case 606175198: return new CustomerImpl();
case 3143044: return new FilmImpl();
case 637325178: return new FilmActorImpl();
case 205122905: return new FilmCategoryImpl();
case 1087251704: return new FilmTextImpl();
case 2020599460: return new InventoryImpl();
case 1613589672: return new LanguageImpl();
case 786681338: return new PaymentImpl();
case 934576860: return new RentalImpl();
case 109757152: return new StaffImpl();
case 109770977: return new StoreImpl();
case 1340382024: return new ActorInfoImpl();
case 2143869857: return new CustomerListImpl();
case 1087486343: return new FilmListImpl();
case 970270416: return new NicerButSlowerFilmListImpl();
case 47400380: return new SalesByFilmCategoryImpl();
case 58908876: return new SalesByStoreImpl();
case 260666013: return new StaffListImpl();
}
return null;
}
}
}
The PortableFactory objects are automatically added by the generated Configuration classes.
Class Definitions
The HazelcastToolBundle automatically generates ClassDefinition objects for each entity type. ClassDefinitiona are used by Hazelcast to internally define how the entity classes look like.
For the Sakila sample database table “film”, the following ClassDefinition objects are generated:
public class FilmClassDefinition extends GeneratedFilmClassDefinition {}
As can be seen, ClassDefinition class just inherits all its methods from another generated class. This allows the possibility to override generated methods with custom code that is retained between re-generation of code.
@GeneratedCode("Speedment")
public abstract class GeneratedFilmClassDefinition implements IntFunction<ClassDefinition> {
protected GeneratedFilmClassDefinition() {}
@Override
public ClassDefinition apply(int version) {
return new ClassDefinitionBuilder(1321754994, 3143044, version)
.addIntField("film_id")
.addUTFField("title")
.addUTFField("description")
.addLongField("release_year")
.addBooleanField("__null__release_year")
.addShortField("language_id")
.addShortField("original_language_id")
.addBooleanField("__null__original_language_id")
.addShortField("rental_duration")
.addUTFField("rental_rate")
.addIntField("length")
.addBooleanField("__null__length")
.addUTFField("replacement_cost")
.addUTFField("rating")
.addUTFField("special_features")
.addLongField("last_update")
.build();
}
}
The ClassDefinition objects are automatically added by the generated Configuration classes.
Supported Data Types
The following Java data types are supported:
- byte, Byte
- short, Short
- int, Integer
- long, Long
- float, Float
- double, Double
- BigInteger
- BigDecimal
- Enum
- boolean, Boolean
- String
- Timestamp
- Time
- Date
- BLOB CLOB and Text columns are supported via String mapping.
For each column, there are a number of type mapping possibilities that can be applied using the UI Tool.
Null Handling
Via the UI Tool, nullable columns can be configured to use getters returning either null (i.e standard POJO) or Optional objects.
Configuration
The Hazelcast Auto DB Integration tool generates a complete class that provides a Hazelcast ClientConfiguration containing all serialization factories and class definitions already pre-configured.
This class is named after the project name. For example, for a project named “Sakila”, then the configuration class will be named SakilaHazelcastConfigComponent.
This is how an exemplary generated class looks like:
public class SakilaHazelcastConfigComponent extends GeneratedSakilaHazelcastConfigComponent {}
As can be seen, this class just inherits all its methods from another generated class. This allows the possibility to override generated methods with custom code that is retained between re-generation of code.
If you want to change the default configuration, there is a better way than overriding this class. Read about HazelcastConfigModifierComponent.
@GeneratedCode("Speedment")
public class GeneratedSakilaHazelcastConfigComponent implements HazelcastConfigComponent {
protected GeneratedSakilaHazelcastConfigComponent() {}
@Override
public ClientConfig get() {
final ClientConfig clientConfig = new ClientConfig();
addPortableFactories(clientConfig);
addClassDefinitions(clientConfig);
return clientConfig;
}
protected void addPortableFactories(ClientConfig clientConfig) {
clientConfig.getSerializationConfig()
.addPortableFactory(1321754994, new SakilaSakilaPortableFactory())
;
}
protected void addClassDefinitions(ClientConfig clientConfig) {
clientConfig.getSerializationConfig()
.addClassDefinition(new ActorClassDefinition().apply(0))
.addClassDefinition(new AddressClassDefinition().apply(0))
.addClassDefinition(new CategoryClassDefinition().apply(0))
.addClassDefinition(new CityClassDefinition().apply(0))
.addClassDefinition(new CountryClassDefinition().apply(0))
.addClassDefinition(new CustomerClassDefinition().apply(0))
.addClassDefinition(new FilmClassDefinition().apply(0))
.addClassDefinition(new FilmActorClassDefinition().apply(0))
.addClassDefinition(new FilmCategoryClassDefinition().apply(0))
.addClassDefinition(new FilmTextClassDefinition().apply(0))
.addClassDefinition(new InventoryClassDefinition().apply(0))
.addClassDefinition(new LanguageClassDefinition().apply(0))
.addClassDefinition(new PaymentClassDefinition().apply(0))
.addClassDefinition(new RentalClassDefinition().apply(0))
.addClassDefinition(new StaffClassDefinition().apply(0))
.addClassDefinition(new StoreClassDefinition().apply(0))
.addClassDefinition(new ActorInfoClassDefinition().apply(0))
.addClassDefinition(new CustomerListClassDefinition().apply(0))
.addClassDefinition(new FilmListClassDefinition().apply(0))
.addClassDefinition(new NicerButSlowerFilmListClassDefinition().apply(0))
.addClassDefinition(new SalesByFilmCategoryClassDefinition().apply(0))
.addClassDefinition(new SalesByStoreClassDefinition().apply(0))
.addClassDefinition(new StaffListClassDefinition().apply(0))
;
}
}
Thus, the generated configuration class adds all the portable serialization factories and all class definitions that has been automatically generated. This class is automatically added as a component by the application builder.
Custom Configuration
Custom configuration can be injected using any class(es) that implements HazelcastConfigModifierComponent as examplified hereunder:
public class MyHazelcastConfigModifierComponent implements HazelcastConfigModifierComponent {
@Override
public ClientConfig apply(ClientConfig clientConfig) {
System.out.println("My custom changes were applied");
clientConfig.getNetworkConfig().addAddress("192.168.0.234:8234");
return clientConfig;
}
}
This class is then injected into the application builder as shown here:
final Speedment hazelcastApp = new SakilaApplicationBuilder()
.withPassword("sakila-password")
.withBundle(HazelcastBundle.class)
.withComponent(MyHazelcastConfigModifierComponent.class)
.build();
This will add the address 192.168.0.234:8234 to the Hazelcast client’s network address and will print:
My custom changes were applied
Any number of HazelcastConfigModifierComponent classes may be added to the builder and they will be applied in order of injection.
Ingesting Data via a Client
Ingest of data from the database into the Hazelcast cluster can be made in many ways.
Generated Ingest Main Method
The ‘HazelcastToolBundle’ generates a default ingest main method that can be used to ingest data as depicted below:
public final class SakilaIngest {
public static void main(final String... argv) {
if (argv.length == 0) {
System.out.println("Usage: " + SakilaIngest.class.getSimpleName() + " database_password");
} else {
try (Speedment app = new SakilaApplicationBuilder()
.withPassword(argv[0]) // Get the password from the first command line parameter
.withBundle(HazelcastBundle.class)
.build()) {
IngestUtil.ingest(app).join();
}
}
}
}
Just calling this main method with a single command line argument with the password of the database will take care of the entire ingest procedure.
Custom Ingest Methods
Ingesting data from a database into the Hazelcast server nodes is greatly simplified with a provided utility class named IngestUtil.
The following example shows a method that will invoke a method IngestUtil::ingest to ingest data from all tables in the the database into the Hazelcast server grid:
public void ingestAll() {
// Create a Speedment application connected to a SQL database
// and that also contains a Hazelcast client
final Speedment app = new SakilaApplicationBuilder()
.withPassword("sakila-password")
.withBundle(HazelcastBundle.class)
.build();
// Ingest all tables from the database into the Hazelcast
// server grid using the default IngestConfiguration:
// - Load all data (i.e. all rows) from the tables
// - Use the default ForkJoin pool for parallel loading
// - Perform loading outside any database transaction
// - Do not clear the maps before loading
CompletableFuture<Void> job = IngestUtil.ingest(app);
// Wait for the ingest job to complete
job.join();
// Print out att the distributed maps that now has been
// created and populated with data
app.getOrThrow(HazelcastInstanceComponent.class).get()
.getDistributedObjects()
.stream()
.sorted(comparing(Object::toString))
.forEach(System.out::println);
// Close the app and thereby also the hazelcastInstance
app.stop();
}
This produces the following output showing all the IMap objects in which data was ingested:
FlakeIdGenerator{name='sakila.sakila.actor_info'}
FlakeIdGenerator{name='sakila.sakila.customer_list'}
FlakeIdGenerator{name='sakila.sakila.film_list'}
FlakeIdGenerator{name='sakila.sakila.nicer_but_slower_film_list'}
FlakeIdGenerator{name='sakila.sakila.sales_by_film_category'}
FlakeIdGenerator{name='sakila.sakila.sales_by_store'}
FlakeIdGenerator{name='sakila.sakila.staff_list'}
IMap{name='sakila.sakila.actor'}
IMap{name='sakila.sakila.actor_info'}
IMap{name='sakila.sakila.address'}
IMap{name='sakila.sakila.category'}
IMap{name='sakila.sakila.city'}
IMap{name='sakila.sakila.country'}
IMap{name='sakila.sakila.customer'}
IMap{name='sakila.sakila.customer_list'}
IMap{name='sakila.sakila.film'}
IMap{name='sakila.sakila.film_actor'}
IMap{name='sakila.sakila.film_category'}
IMap{name='sakila.sakila.film_list'}
IMap{name='sakila.sakila.film_text'}
IMap{name='sakila.sakila.inventory'}
IMap{name='sakila.sakila.language'}
IMap{name='sakila.sakila.nicer_but_slower_film_list'}
IMap{name='sakila.sakila.payment'}
IMap{name='sakila.sakila.rental'}
IMap{name='sakila.sakila.sales_by_film_category'}
IMap{name='sakila.sakila.sales_by_store'}
IMap{name='sakila.sakila.staff'}
IMap{name='sakila.sakila.staff_list'}
IMap{name='sakila.sakila.store'}
Note: The FlakeIdGenerator objects are used for tables/views that have no primary key.
The utility class IngestUtil contains a number of related methods that can be used to control the ingest process in more detail, including:
- Selecting a custom
ExecutorServiceused to ingest data - Selecting a database transaction to use during data ingest
- Applying arbitrary
Streamoperators on the database source Stream (e.g. limiting or filtering the database content) - Clearing all data before start of data ingest
- Selecting a subset of database tables to use during ingest
See the JavaDoc for the classes IngestUtil and IngestConfiguration for a detailed description on these features.
The code above can be shortened like this (provided that the print out section is skipped):
public void ingestAllShort() {
try (Speedment app = new SakilaApplicationBuilder()
.withPassword("sakila-password")
.withBundle(HazelcastBundle.class)
.build()) {
IngestUtil.ingest(app).join();
};
}
Query Data
Data can be queried using at least three different methods:
- Hazelcast IMap API
- Hazelcast Jet (distributed streams)
- Standard Java Streams
Hazelcast Map
Applications can use the Hazelcast Map and IMap interfaces directly and work with data this way. The name of a distributed map can be obtained using the HazelcastMapUtil::mapName method as shown hereunder:
String filmMapName = HazelcastMapUtil.mapName(FilmManager.IDENTIFIER);
Read more on the Hazelcast IMap API here
Hazelcast Jet
Read more on connecting Hazelcast Jet to Hazelcast IMap objects here
Streams
As for all Speedment applications, data in the Hazelcast grid can be queried using standard java.util.stream.Stream objects.
Here is an example where we are collecting a list of the film titles (in alphabetical order) of the films with a rating of PG-13 that has a length greater or equal to 180 minutes:
FilmManager films = hazelcastApp.getOrThrow(FilmManager.class);
List<String> list = films.stream()
.filter(Film.RATING.equal("PG-13"))
.filter(Film.LENGTH.greaterOrEqua(180))
.map(Film.TITLE)
.sorted()
.collect(Collectors.toList());
Read more about Speedment streams here (examples) and here (stream fundamentals)
Other Languages
Because data is stored using Portable entity classes, data in the Hazelcast server nodes can also be queried using other languages. Read more here.
null values explicitly in your predicates if you have Wrapper classes (e.g. Integer, Long, Double) that are nullable.
Persistence
The standard Speedment CRUD operations API apply to Hazelcast in the same way as for other data sources. Please refer to that section of the user guide for examples of Speedment powered CRUD operations.
A Speedment application configured with a Hazelcast bundle will provide managers that handle persistence to both the Hazelcast grid and the underlying database making sure the underlying database serves as source of truth and that the Hazelcast data grid is eventually consistent with that source of truth.
By persisting to both, the Speedment runtime maintains the consistency between the relational database and the data grid. This of course assumes that only Speedment applications perform data altering operations on the data grid.
Persisting to Hazelcast Grid only
The Speedment application can be configured to operate on the Hazelcast grid only and not persist any data to the relational database by setting the ‘hazelcast.writethrough’ parameter to “false” as follows.
Speedment hazelcastApp = new SakilaApplicationBuilder()
.withPassword("sakila-password")
.withBundle(HazelcastBundle.class)
.withParam("hazelcast.writethrough", "false")
.build();
Persisting Server-Side via MapStore/MapLoader
Instead of using persistence via a client, it is also possible to use server-side persistence via the MapStore/MapLoad interfaces. There are different pros and cons of this compared to Client based persistence.
Pros
- Server nodes can load entities that belongs to its partitions directly
- Server nodes can load entities in parallel, independent of other server nodes
- Hazelcast maps can be loaded lazilly.
Cons
- The Java Domain Model needs to be present on the server classpath
- The server nodes need to know the database password
- The server nodes need to be able to access the database
The HazelcastToolBundle automatically generates MapStore objects for each entity type:
public class FilmMapStore extends GeneratedFilmMapStore {
public FilmMapStore(Manager<Film> manager) {
super(manager);
}
}
As can be seen, an entity implementation class just inherits all its methods from another generated class. This allows the possibility to override generated methods with custom code that is retained between re-generation of code.
@GeneratedCode("Speedment")
public abstract class GeneratedFilmMapStore extends AbstractMapStore<Integer, Film> {
protected GeneratedFilmMapStore(Manager<Film> manager) {
super(manager, Film.FILM_ID, new FilmImpl()::setFilmId);
}
}
In order to initialize a FilmMapStore we need a Manager<Film> that can be retrieved directly from a Speedment instance as shown in the following example:
public static final String MAP_NAME = HazelcastMapUtil.mapName(FilmManager.IDENTIFIER);
public static void main(String... args) {
final Speedment speedment = new SakilaApplicationBuilder()
.withPassword("sakila-password")
.withBundle(HazelcastServerBundle.class) // Use this Bundle server-side
.build();
// Creates a config with pre-configured serialization factories an more
final Config config = new SakilaHazelcastServerConfigComponent().get();
MapStoreConfig mapStoreConfig = new MapStoreConfig();
mapStoreConfig.setImplementation(new FilmMapStore(speedment.getOrThrow(FilmManager.class)));
mapStoreConfig.setWriteDelaySeconds(0);
mapStoreConfig.setInitialLoadMode(MapStoreConfig.InitialLoadMode.EAGER);
MapConfig mapConfig = config.getMapConfig(MAP_NAME);
mapConfig.setMapStoreConfig(mapStoreConfig);
final HazelcastInstance instance = Hazelcast.newHazelcastInstance(config);
IMap<Integer, Film> map = instance.getMap(MAP_NAME);
System.out.println("map.size() = " + map.size());
instance.shutdown();
speedment.stop();
}
This will produce the following output:
map.size() = 1000
As can be seen, the film map was pre-loaded by the server using the generated FilmMapLoader.
Both write-through and write-back modes are supported.
MapStore/MapLoader classes are only generated for tables with exactly one primary key.Transactions
Speedment transaction handling is further described here and applies to the relational database in the same way when using the Hazelcast bundle. In the current version of the Hazelcast bundle, the operations on the Hazelcast data grid are not covered by transactional locks. This is likely to change in some future release of the Hazelcast bundle where also operations on the data grid may support transactions.
Indexing
Upon generation, the Hazelcast Auto DB Integration tool examines the database metadata and suggests indexing based on how the database is indexed. This provides a solid baseline for grid indexing. In the following example, an index utility method was automatically generated when working with the Sakila database (the class has been shortened for brevity):
@GeneratedCode("Speedment")
public final class GeneratedSakilaIndexUtil {
private GeneratedSakilaIndexUtil() {}
public static void setupIndex(final HazelcastInstance h) {
// Indexes for table actor
// Index PRIMARY (unique) using column actor_id
h.getMap("sakila.sakila.actor").addIndex("actor_id", true);
// Index idx_actor_last_name using column last_name
h.getMap("sakila.sakila.actor").addIndex("last_name", true);
// ... Rows hidden for brevity
// Indexes for table film
// Index PRIMARY (unique) using column film_id
h.getMap("sakila.sakila.film").addIndex("film_id", true);
// Index idx_film_rating using column rating
h.getMap("sakila.sakila.film").addIndex("rating", true);
// Index idx_fk_language_id using column language_id
h.getMap("sakila.sakila.film").addIndex("language_id", true);
// Index idx_fk_original_language_id using column original_language_id
h.getMap("sakila.sakila.film").addIndex("original_language_id", true);
// Index idx_title using column title
h.getMap("sakila.sakila.film").addIndex("title", true);
// ... Rows hidden for brevity
}
}
As can be seen, creating a HazelcastInstance and then just invoking the method GeneratedSakilaIndexUtil::setupIndex will create the same indexes in the Hazelcast grid that were present in the database.
Joins
Hazelcast tables can be joined using the Stream Join functionality. The current Hazelcast version does not support joining of Hazelcast Maps using the JoinComponent. Read more about joins with Speedment here.
Aggregations
Aggregations using the Speedment Aggregator are supported with Hazelcast maps but are not fully optimized in the current version.
Aggregations using the Hazelcast IMap::aggregate method is fully supported.
Performance
Thanks to the Portable entity classes, Hazelcast server nodes can benefit from indexing and partial deserialization when applying predicates on large data sets. This greatly speeds up querying in many cases.
Example Clients
The following examples show different variants of Hazelcast clients that can connect to a Hazelcast server grid that already contains data (e.g. by means of the ingest feature):
Using the Hazelcast IMap API
This example is using the native Hazelcast IMap interface to select data from a Hazelcast server grid:
public class IMapClientExample {
public static void main(String... args) {
// Create the Speedment instance with the HazelcastBundle
Speedment hazelcastApp = new SakilaApplicationBuilder()
.withPassword("sakila-password")
.withBundle(HazelcastBundle.class)
.build();
// Retrieve the HazecastInstance from the app
HazelcastInstance hazelcastClient = hazelcastApp.getOrThrow(HazelcastInstanceComponent.class).get();
// Calculate the IMap name given a TableIdentifier
String mapName = mapName(FilmManager.IDENTIFIER);
IMap<Integer, Film> filmMap = hazelcastClient.getMap(mapName);
Predicate predicate = new SqlPredicate("rating = 'PG-13' and length >= 180");
Collection<Film> collection = filmMap.values(predicate);
// print out all Film entities that matches the predicates
collection
.forEach(System.out::println);
// Close the hazelcastApp which, in turn, stops the hazelcastClient
hazelcastApp.stop();
}
}
The code above can be shortened like this:
try(Speedment app = new SakilaApplicationBuilder()
.withPassword("sakila-password")
.withBundle(HazelcastBundle.class)
.build()) {
app.getOrThrow(HazelcastInstanceComponent.class)
.get()
.getMap(mapName(FilmManager.IDENTIFIER))
.values(new SqlPredicate("rating = 'PG-13' and length >= 180"))
.forEach(System.out::println);
}
Using the Speedment Stream API
This example is using the Speedment Stream API to select data from a Hazelcast server grid:
public class StreamClientExample {
public static void main(String... args) {
// Create the Speedment instance with the HazelcastBundle
Speedment hazelcastApp = new SakilaApplicationBuilder()
.withPassword("sakila-password")
.withBundle(HazelcastBundle.class)
.build();
// Retrieve the FilmManager from the app
FilmManager films = hazelcastApp.getOrThrow(FilmManager.class);
// Print out all Film entities that matches the predicates
films.stream()
.filter(Film.RATING.equal("PG-13"))
.filter(Film.LENGTH.greaterOrEqual(180))
.forEach(System.out::println);
// Close the hazelcastApp which, in turn, stops the hazelcastClient
hazelcastApp.stop();
}
}
The code above can be shortened like this:
try (Speedment app = new SakilaApplicationBuilder()
.withPassword("sakila-password")
.withBundle(HazelcastBundle.class)
.build()) {
app.getOrThrow(FilmManager.class).stream()
.filter(Film.RATING.equal("PG-13"))
.filter(Film.LENGTH.greaterOrEqual(180))
.forEach(System.out::println);
}
Hazelcast cloud
Hazelcast Auto DB Integration verison 3.1.14 and later are ready for usage in Hazelcast cloud. A cloud instance is defined by three
parameters - the name, the group password and the discovery token. These three are supplied to Hazelcast Auto DB Integration
via a HazelcastCloudConfig as follows.
Speedment hazelcastApp = new SakilaApplicationBuilder()
.withPassword("sakila-password")
.withBundle(HazelcastBundle.class)
.withComponent(HazelcastCloudConfig.class, () -> HazelcastCloudConfig.create(
"<name of cluster>",
"<cluster password>",
"<discovery token>")
)
.build();
Questions and Discussion
If you have any question, don’t hesitate to reach out to the Speedment developers on Gitter.