What is DataStore?
The Speedment HyperStream DataStore is included in a proprietary module for Speedment that stores database entities in-JVM-memory, allowing database queries to be performed extremely fast, utilizing the Java 8 Stream API to the fullest.
A Stream does not describe any details about how data is retrieved, in fact this is delegated to the framework defining the pipeline source and termination. There is nothing in the design of a Stream entailing data must come from a SQL query. This fact is used by DataStore which allows streams to connect directly to RAM instead of remote databases.
The engine provides streams through exactly the same API semantics as for databases but will execute queries with orders of magnitude lower latencies. This creates a new way to write high performance data applications whereby the actual source-of-truth can remain with an existing database. It is possible to provision terabytes of data in the JVM with no garbage collection impact because data is stored off-heap and can optionally be mapped to SSD files. Streams can have a latency well under one microsecond. Comparing this to a traditional application with a database connection, just the TCP round-trip delay in a high-performance network is hardly ever under 40 microseconds and then database latency and data transfer times have to be added on top.
Thus, the DataStore module is best suited for read-intensive applications, like analytics.
Enabling DataStore
In order to use DataStore you need a Speedment HyperStream license or a trial license key. Download a free trial license using the Speedment Initializer or use HyperStream for Free with databases up to 500 MB.
The DataStore module needs to be referenced both in your pom.xml file and in you application.
POM File
Use the Initializer to get a POM-file template. To use DataStore, add it as a dependency to the speedment-enterprise-maven-plugin and mention it as a component:
<plugin>
<groupId>com.speedment.enterprise</groupId>
<artifactId>speedment-enterprise-maven-plugin</artifactId>
<version>${speedment.enterprise.version}</version>
<dependencies>
<dependency>
<groupId>com.speedment.enterprise</groupId>
<artifactId>datastore-tool</artifactId>
<version>${speedment.enterprise.version}</version>
</dependency>
</dependencies>
<configuration>
<components>
<component>com.speedment.enterprise.datastore.tool.DataStoreToolBundle</component>
</components>
</configuration>
</plugin>
You also have to depend on DataStore as a runtime dependency to your application:
<dependencies>
<dependency>
<groupId>com.speedment.enterprise</groupId>
<artifactId>datastore-runtime</artifactId>
<version>${speedment.enterprise.version}</version>
</dependency>
</dependencies>
Application
When you build the application, the InMemoryBundle needs to be added to the runtime like this:
SakilaApplicationBuilder builder = new SakilaApplicationBuilder()
.withPassword(password)
.withBundle(InMemoryBundle.class);
Using DataStore
Load from the Database
Before DataStore can be used, it has to load all database content into the JVM. This is how it is done:
// Load the in-JVM-memory content into the DataStore from the database
app.getOrThrow(DataStoreComponent.class)
.load();
After the DataStore module has been added and loaded, all stream queries will be made towards RAM instead of the remote database. No other change in the application is needed.
Synchronizing with the Database
If you want to update the DataStore to the latest state of the underlying database, do like this:
// Refresh the in-JVM-memory content from the database
app.getOrThrow(DataStoreComponent.class)
.reload();
This will load a new version of the database in the background and when completed, new streams will use the new data. Old ongoing streams will continue to use the old version of the DataStore content. Once all old streams are completed, the old version of the DataStore content will be released.
Automatic periodic refresh of the DataStoreComponent can easily be made using a Timer (or an ExecutorService) as shown hereunder:
long delay = 10 * 60 * 1_000L;
long period = 10 * 60 * 1_000L; // Refresh each 10:th minute
Timer timer = new Timer();
timer.scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {
app.getOrThrow(DataStoreComponent.class)
.load();
}
},
delay,
period
);
Loading/Reloading with a Particular ExecutorService
By default, DataStore will load and structure data from the database using the common ForkJoinPool. Sometimes loading can take minutes and then it might be desirable to perform loading using a custom executor with perhaps a limited number of threads so that the application can continue to serve requests while loading in the background.
You can provide any executor to the load() and reload() methods like this:
ExecutorService myExecutorService = Executors.newFixedThreadPool(3);
DataStoreComponent dsc = app.getOrThrow(DataStoreComponent.class);
dsc.load(myExecutorService);
...
// Later on
dsc.reload(myExecutorService);
Load/Reload Individual Rows
If you only want to pull in a subset of the database rows, you can use a variant of the load/reload method as shown hereunder:
final StreamSupplierComponentDecorator decorator = StreamSupplierComponentDecorator.builder()
.withStreamDecorator(FilmManager.IDENTIFIER, s -> s.limit(100))
.build();
DataStoreComponent dataStoreComponent = app.getOrThrow(DataStoreComponent.class);
dataStoreComponent.load(ForkJoinPool.commonPool(), decorator);
This will only load the first 100 films from the database. Any stream operation(s) that returns the same stream type (i.e. filter(), sorted(), distinct(), limit() and skip() but not map() and flatMap()) may be applied in the decorator. Specifically, applying the operation s -> s.limit(0) will prevent DataStore from loading any data into memory.
This is useful, for example when working on time based data, in micro service deployments or in various test scenarios.
StreamSupplierComponentDecorator means that you are assuming the responsibility of ensuring referential integrity. If the number of entities are reduced, for example using filter() or limit() operations, then these skipped entities may be referenced by other entities. This must now be handled by your application.
Load/Reload Individual Tables
Sometimes it makes sense to just put a limited set of tables in the DataStore while other tables can be reached via the underlying database. By using the Speedment HyperStream module Meta Stream Supplier, you can select which tables are retrieved from the the DataStore and which tables will be retrieved from the database.
In order to run, the module first needs to be configured using a class that implements the interface MetaStreamSupplierConfigurator. This is how a custom configurator can look like:
public static class MyMetaStreamConfigurator implements MetaStreamSupplierConfigurator {
@Override
public Stream<TableMapping<Class<? extends StreamSupplierComponent>>> tableMappings() {
return Stream.of(
TableMapping.of(FilmManager.IDENTIFIER, DataStoreStreamSupplierComponent.class),
TableMapping.of(ArtistManager.IDENTIFIER, SqlStreamSupplierComponent.class)
);
}
}
This will configure the Meta Stream Supplier to explicitly use the Data Store for the film table and the database for the artist table. Unconfigured tables will default to the top most StreamSupplierComponent (usually the DataStore) but if you like another behavior, just override the MetaStreamSupplierConfigurator::defaultStreamSupplierComponentClass method.
The module is activated by installing the bundle MetaStreamSupplierBundle. Here is an example of how to install the Meta Stream Supplier module:
SakilaApplication app = new SakilaApplicationBuilder()
.withBundle(InMemoryBundle.class);
.withComponent(MyMetaStreamConfigurator.class)
.withBundle(MetaStreamSupplierBundle.class)
.build();
You must also add the following dependency to your pom.xml file:
<dependency>
<groupId>com.speedment.enterprise</groupId>
<artifactId>metastreamsupplier</artifactId>
</dependency>
When you elect to used some tables from the database rather than the DataStore then you usually do not want those tables to take up valuable space in the DataStore since you are not going to use them anyhow. Read more on how to control what data goes into the DataStore here.
StreamSupplierComponent objects are added in a stack. Make sure that you add the MetaStreamSupplierBundle last in you builder and in any case before the InMemoryBundle;
MetaStreamSupplierComponent means that you are assuming the responsibility of ensuring referential integrity. If the MetaStreamSupplierComponent are using components that are from different transaction states, then these component views might violate referential integrity. This must now be handled by your application.
Custom Loading/Reloading
Since 1.1.15, there is a general way of configuring the load process. This way will eventually replace other ways of loading. Loading/reloading is invoked using the DataStoreComponent.createSnapshotJob(LoadConfiguration loadConfiguration). The LoadConfiguration can be obtained using a builder as exemplified below:
StreamSupplierComponentDecorator myDecorator = ...;
Transaction myTransaction = ...;
ExecutorService myExecutor = ...;
LoadConfiguration loadConfiguration = LoadConfiguration.builder()
.withChunkSize(10_000)
.withChunkSize(Films.FILM_ID.identifier().asTableIdentifier(), 5_000)
.withDecorator(myDecorator)
.withExecutor(myExecutor)
.withTransaction(myTransaction)
.build();
DataStoreComponent ds = app.getOrThrow(DataStoreComponent.class);
CompletableFuture<Void> job = ds.createSnapshotJob(loadConfiguration);
| Method | Parameter type | Action |
|---|---|---|
| withChunkSize | chunkSize | Sets the positive chunk size that shall be used for all tables when loading data from the data source unless specifically overridden by the Builder.withChunkSize(tableIdentifier, chunkSize) method. The default chunk size is Long.MAX_VALUE meaning no chunk loading shall be used. Chunk loading can sometimes improve load performance for some database types. |
| withChunkSize | tableIdentifier, chunkSize | Sets the positive chunk size that shall be used for the given tableIdentifier when loading data from the data source. The default chunk size is Long.MAX_VALUE meaning no chunk loading shall be used. Chunk loading can sometimes improve load performance for some database types. |
| withDecorator | decorator | Sets the decorator to use when creating a data snapshot. The default decorator is the StreamSupplierComponentDecorator.identity() decorator that does not modify any stream. |
| withExecutor | executor | Sets the executor to use when creating a data snapshot. The default executor is the ForkJoinPool.commonPool() |
| withExecutor | executor | Sets the Transaction that shall be used when creating a data snapshot. The default transaction is no transaction. |
Showing The Load/Reload Progress
The load and organize process can be viewed in the log by enabling APPLICATION_BUILDER logging as shown hereunder:
SakilaApplicationBuilder builder = new SakilaApplicationBuilder()
.withPassword(password)
.withLogging(LogType.APPLICATION_BUILDER)
.withBundle(InMemoryBundle.class);
.build();
When the DataStore is loaded, information on the loading progress will be shown in the logs:
2017-05-16T01:46:16.901Z DEBUG [pool-1-thread-3] (#APPLICATION_BUILDER) - db0.sakila.category : Loading from database completed (took 136.76 ms).
2017-05-16T01:46:16.939Z DEBUG [pool-1-thread-1] (#APPLICATION_BUILDER) - db0.sakila.actor : Loading from database completed (took 195.63 ms).
2017-05-16T01:46:16.948Z DEBUG [pool-1-thread-1] (#APPLICATION_BUILDER) - db0.sakila.actor : Building entity cache with 200 rows completed (took 7.98 ms). Density is 31 bytes/entity
2017-05-16T01:46:16.948Z DEBUG [pool-1-thread-3] (#APPLICATION_BUILDER) - db0.sakila.category : Building entity cache with 16 rows completed (took 46.12 ms). Density is 20 bytes/entity
2017-05-16T01:46:16.985Z DEBUG [pool-1-thread-1] (#APPLICATION_BUILDER) - db0.sakila.country : Loading from database completed (took 36.65 ms).
2017-05-16T01:46:16.995Z DEBUG [pool-1-thread-1] (#APPLICATION_BUILDER) - db0.sakila.country : Building entity cache with 109 rows completed (took 8.78 ms). Density is 24 bytes/entity
2017-05-16T01:46:17.007Z DEBUG [pool-1-thread-2] (#APPLICATION_BUILDER) - db0.sakila.address : Loading from database completed (took 252.67 ms).
...
2017-05-16T01:46:18.732Z DEBUG [pool-1-thread-1] (#APPLICATION_BUILDER) - rental.rental_date : Loading column store
2017-05-16T01:46:18.743Z DEBUG [pool-1-thread-3] (#APPLICATION_BUILDER) - rental.inventory_id : Building column cache with 16,044 rows completed (took 53.60 ms). Density is 4 bytes/entity
2017-05-16T01:46:18.743Z DEBUG [pool-1-thread-3] (#APPLICATION_BUILDER) - rental.rental_id : Loading column store
2017-05-16T01:46:18.745Z DEBUG [pool-1-thread-1] (#APPLICATION_BUILDER) - rental.rental_date : Building column store
2017-05-16T01:46:18.748Z DEBUG [pool-1-thread-2] (#APPLICATION_BUILDER) - rental.return_date : Building column cache with 16,044 rows completed (took 97.70 ms). Density is 4 bytes/entity
2017-05-16T01:46:18.750Z DEBUG [pool-1-thread-3] (#APPLICATION_BUILDER) - rental.rental_id : Building column store
2017-05-16T01:46:18.756Z DEBUG [pool-1-thread-3] (#APPLICATION_BUILDER) - rental.rental_id : Building column cache with 16,044 rows completed (took 12.33 ms). Density is 4 bytes/entity
2017-05-16T01:46:18.781Z DEBUG [pool-1-thread-1] (#APPLICATION_BUILDER) - rental.rental_date : Building column cache with 16,044 rows completed (took 47.96 ms). Density is 4 bytes/entity
Finished reloading in 2.05 s.
Disable Unnecessary Indexes
By default, the Datastore indexes every column of every table. However, since the indexes can sometimes take up quite a bit of extra space, you might want to disable indexing on columns that you are not filtering or sorting on directly.
Open the Speedment Tool and go to the column you want to disable indexing for and select “Disable In-Memory Index”.
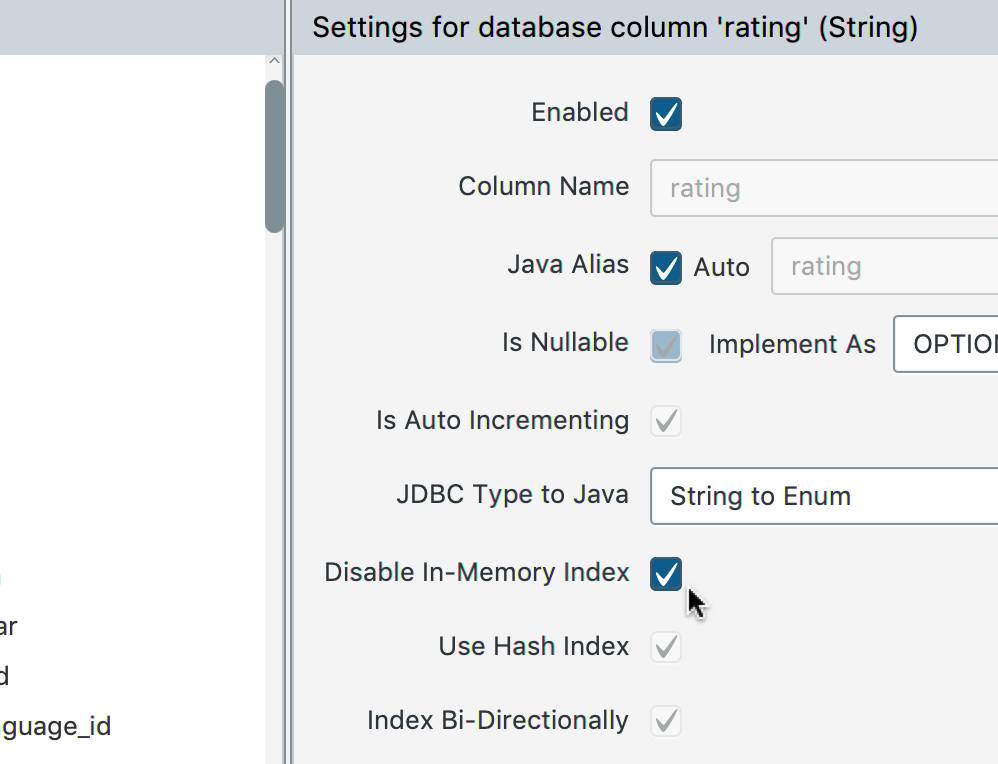
gender, city, category etc), you might want to use the Enum Serializer Plugin for Datastore to convert them into enums. You should also try and use (To Primitive) as the Type Mapper wherever possible.
Optimizing for Low Cardinality
Requires Speedment HyperStream 1.1.15 or later. If you have a column in your database with a very low cardinality, you can get faster load and query times if you mark it as a “Low Cardinality” column in the Speedment Tool.
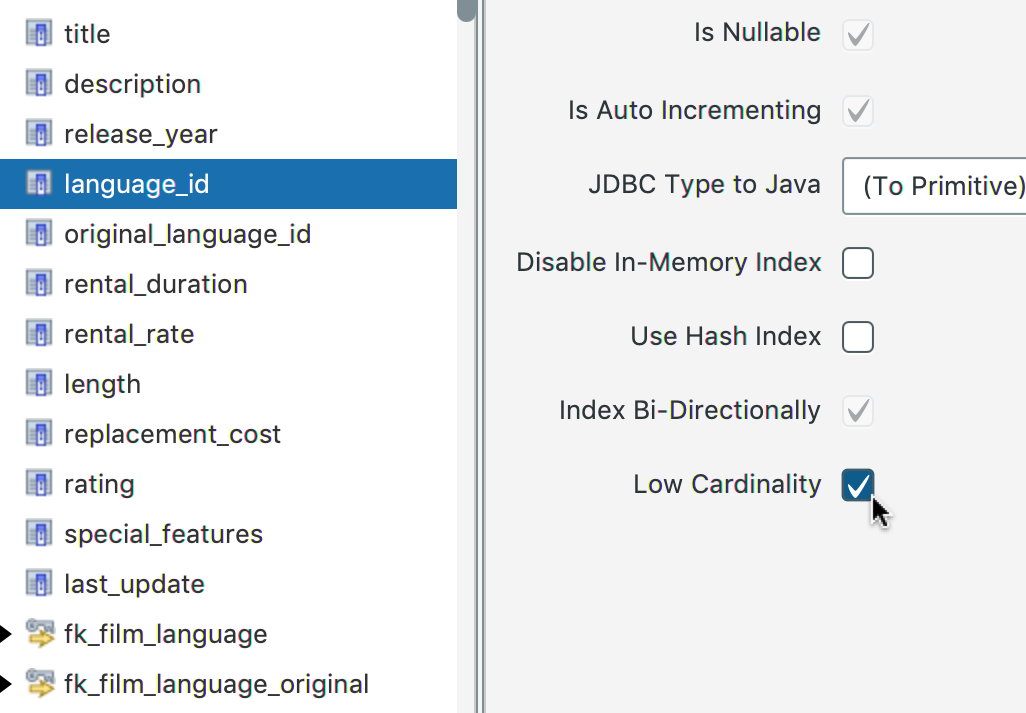
This tells Speedment to do two things:
- Try to optimize storage by removing duplicates
- Create separate buckets for every distinct value in the index
There are however no guarantees that these optimizations will be done, since other factors might make them unnescessary or even slower. Marking columns as “Low Cardinality” is usually a good thing if you have up to a few hundred disinct values.
Creating Multi-Indexes
Speedment HyperStream 1.1.10 introduced the concept of Multi-Indexes which can significantly increase the performance of filters that involve two columns of the same (or similar) type. Multi-Indexes take up the same amount of memory as a single-column index, but can filter both dimensions in O(log N) time-complexity.
To create a Multi-Index for a pair of columns, open the Speedment Tool and right-click on the table.
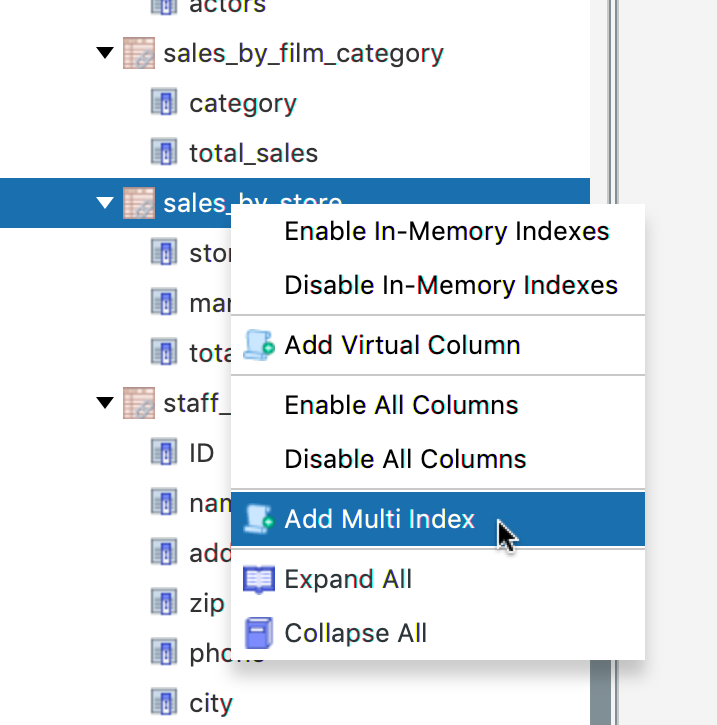
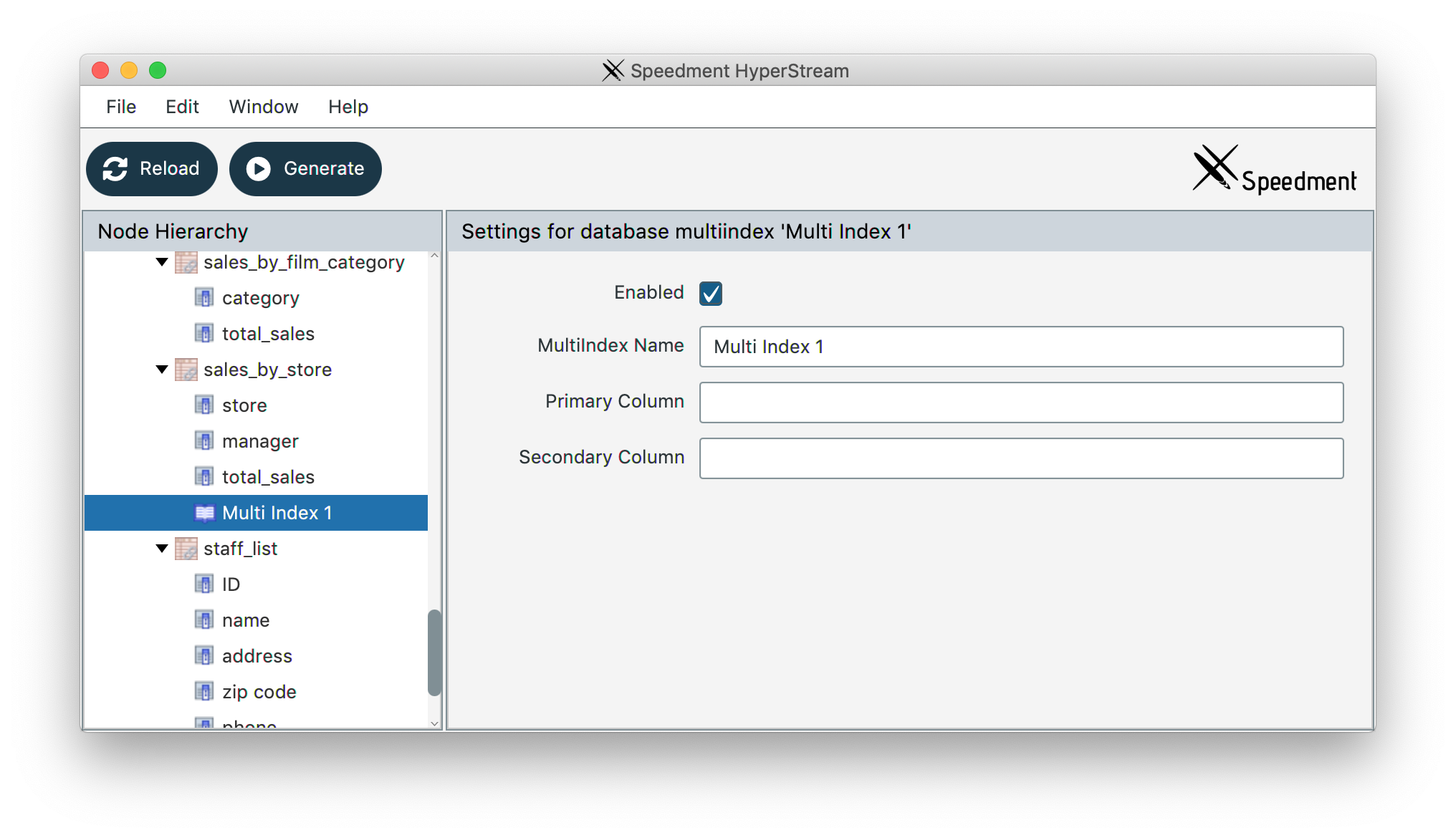
In the dropdown menu, select “Create Multi Index”. Scroll to the bottom of the table and select the newly created index.
On the right side, you can now enter the name of the columns to use as Primary and Secondary sort order. The name must match perfectly the “Database Name” of the columns in question. You may also want to set a custom name for the index. To enable editing, right-click the “MultiIndex Name”-textfield and select “Enable editing”.
Currently, only very specific filters are being considered when interpreting a Speedment Stream for a Multi-Index. To make sure a filter is optimized correctly, it should be written as a .and()-combination of two regular Speedment filters.
Example Usage:
flights.stream()
.filter(Flight.ORIGIN.equal("SFO")
.and(Flight.DESTINATION.equal("LAX"))
)
.skip(100_000).limit(1_000)
.collect(toList());
Only equal- and in-operators can be optimized using multi-indexes.
Obtaining Statistics
You can obtain statistics on how tables, columns and memory segments are used by invoking the DataStoreComponent::getStatistics method. Here is an example of how to print out DataStore statistics.
app.get(DataStoreComponent.class)
.map(DataStoreComponent::getStatistics)
.map(StatisticsUtil::prettyPrint)
.ifPresent(s -> s.forEachOrdered(System.out::println));
This will produce an output that starts like this:
| Table | Column | Off_Heap [B] | Rows | Nulls | Cardinality | Type | Class | Distinct |
|---|---|---|---|---|---|---|---|---|
| actor | - | 6307 | 200 | - | - | Table | SingleSegmentEntityStore | - |
| actor | actor_id | 400 | - | 0 | - | Column | IndexedIntFieldCache | true |
| actor | first_name | 400 | - | 0 | - | Column | IndexedStringFieldCache | false |
| actor | last_name | 400 | - | 0 | - | Column | IndexedStringFieldCache | false |
| actor | last_update | 400 | - | 0 | - | Column | IndexedComparableFieldCache | false |
| address | - | 66286 | 603 | - | - | Table | SingleSegmentEntityStore | - |
| address | address | 2412 | - | 0 | - | Column | IndexedStringFieldCache | false |
| address | address2 | 2404 | - | 4 | - | Column | IndexedStringFieldCache | false |
| address | address_id | 2412 | - | 0 | - | Column | IndexedIntFieldCache | true |
…
Clear the DataStore
You can explicitly clear the content of the DataStore by calling the clear() method as shown below. After the clear method has been called, streams are not available and a DataStoreNotLoadedException will be thrown if a stream is requested.
// Clear the DataStore and release all in-JVM-memory resources
app.get(DataStoreComponent.class)
.ifPresent(DataStoreComponent::clear);
// Streams are now served by the database instead of DataStore
If load() is called after clear(), streams can again be served by DataStore.
Limiting Memory Usage
It is possible to set the maximum amount of allowable off-heap memory to be allocated by using the “-XX:MaxDirectMemorySize” JVM flag.
Performance
The DataStore module will sort each table and each column upon load/re-load. This means that you can benefit from low latency regardless on which column you use in stream filters, sorters, etc.
When the DataStore module is being used, Stream latency will be orders of magnitudes better.
Questions and Discussion
If you have any question, don’t hesitate to reach out to the Speedment developers on Gitter.